
Archive for the ‘Opinion’ Category
Concurrency: Are We Focusing On the Wrong Thing?
It is fairly widely accepted that concurrent programming is becoming more important, and that this trend will only accelerate over coming years. This can be traced back to Herb Sutter’s excellent article The Free Lunch Is Over, which elaborates on how we hit the wall in terms of CPU clock speed around 2003, and further CPU performance has concentrated on hyperthreading and multicore ever since. The figure used in that article is such a dramatic illustration that I’ve seen it used dozens of times in talks and articles since:
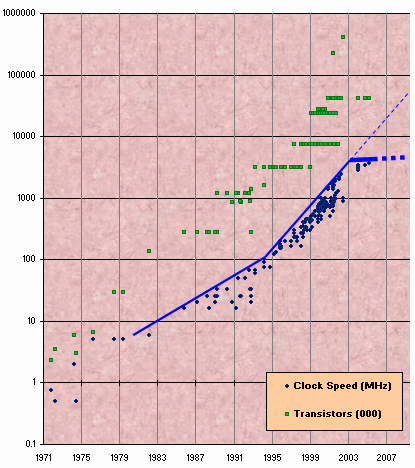
But something bothers me in all the talk about concurrency, and I think it derives from focusing too much on speed. It is true that CPU-bound applications no longer benefit from the “free lunch” of increasing clock speeds. However, I would contend that the vast majority of applications are not CPU bound. Further, many applications that do need a lot of CPU power are already naturally parallelisable: such as the fast-growing category of multi-user web applications.
So although clock speeds have stagnated, for many programmers it won’t have any real performance impact. Most desktop applications will get along just fine, still bound on I/O or a squishy, organic, slow-moving user. Web applications will naturally take advantage of more cores as they appear. The only programmers likely to notice the performance impact are those working in areas where performance has always been at the bleeding edge, which frankly is a small minority.
This doesn’t mean we’re all off the hook, though. Even though few of us write CPU-bound code, many more of us write multithreaded code. Badly. The only reason our code works is because it isn’t run on truly multi-processor systems, and certainly not on systems with dozens of CPUs (or more). Whole classes of concurrency bugs don’t show up until code is stressed on highly parallelised hardware. And it just gets worse as more CPUs or cores are added. We’ve got away with this for a while, but when every desktop has dozens of cores, ignorance will cease to be bliss.
Sutter’s article covers these points, but like most other discussions I think it both underplays them relative to the performance issues, and underestimates how difficult it is to learn concurrent programming. This is a much greater challenge than learning a design technique like OO — concurrent programs, at least those using current locking techniques, are insanely hard to reason about. The true solution, in the opinion of many (myself included), is to move away from shared memory and explicit locking as much as possible. This is a key reason why pure functional programming is seeing a resurgence.
Sutter was right: the free lunch is over. Only it’s not performance we’ll have to pay for: it’s correctness.
Four Simple Rules For Mocking
Lately I’ve been thinking about how I approach mocking in my tests, and why it is that I like Mockito so much. I find that I follow a few simple rules:
- Don’t Mock: where possible, I prefer to use real implementations rather than mocks. Using real implementations is usually easier, is closer to reality (which is the ultimate test). So I only mock when real implementations are too hard to control, or too slow.
- Don’t Mock, Fake: if speed is the problem, instead of immediately reaching for a mock, I first consider if there is an alternative implementation. The classic example is an in-memory implementation of what would usually be a slow external resource (like a file system or database). This is a middle ground — close to reality, but fast enough to keep the test suite snappy.
- Don’t Mock, Stub: I prefer not to verify directly using mocks, as this risks testing the implementation of the unit rather than its interface. So even when using a mocking library, I prefer to stub behaviour and assert based on the output and state of the unit.
- OK, Mock: if I strike out on rules 1, 2 and 3, I know I’ve hit the sweet spot for full-blown mocking.
My conclusion is that although mocks are a powerful and necessary tool, my personal tendency is to avoid them until absolutely necessary. Even when I use mocks, I avoid verification where possible. This is why Mockito works so well — because it favours stubbing with selective verification over the classical expect-run-verify model.
Overcoming Coder’s Block
Sometimes I completely run out of answers. Other times I have too many answers. Either way, I end up staring stupidly at the screen achieving nothing (well, OK, reading blogs). Here are a few techniques I use to help get unstuck:
- Pros and Cons: when I have too many answers, I try to make it objective by drawing up the pros and cons and seeing where that takes me.
- Simplify: like a lot of developers, I can be prone to over-analyse when I am stuck on an issue for a while. So I remind myself to try simplifying the problem. Often by dropping a layer of flexibility the problem is a lot easier to solve. If I really need the flexibility, I can add it later when I have greater understanding.
- Take a Break: sometimes I’m just trying too hard, and need to step back. I work from home, so a short walk outside is a welcome break. Actually getting away from the computer relaxes the grey matter. The vitamin D doesn’t hurt either ? .
- Explain the Problem: very often I find that while I’m explaining the problem, I see it in a different way. If not, the input of another person usually throws a different perspective on the issue. If there’s nobody to bother immediately, just writing down an explanation can help.
- Switch Gears: this works when I’m getting frustrated by a lack of progress. By switching to a small, unrelated task, I can Get Something Done and develop some new momentum. This also serves as a break from the original problem.
- Write Some Tests: I don’t practice TDD all the time, but when I’m stuck trying to understand how things work, writing some tests first can be very illuminating. Having tests in place also gives gratifying feedback as I finally start to crack the underlying problem. I find this works best for really tough technical issues, where good test coverage is even more important than normal.
- Write Some Code: if I have a partial solution, even if I know it is ugly or inadequate, sometimes I’ll just plow ahead anyway. Actually working through a throwaway implementation is better than standing still, as it turns up all the little details. I’m happy to throw that code away since I know the alternative was not getting anywhere.
So, should you be reading this, or taking a walk..? ?
Languages, Complexity and Shifting Work
One of the things that bothers me about the rise of dynamic languages is the nagging thought that work is being shifted the wrong way. Generally speaking, we programmers all become more productive as work is shifted down to lower levels. The smarter the toolchain, the less we need to bother with incidental details, leaving us to focus on Real Problems. Sure, someone needs to program that toolchain, but once that is done by the few the benefits can be reaped by the many.
What does this have to do with dynamic languages? Well, a lot of the productivity benefits of these languages come from their support for higher levels of abstraction. Think first class functions, closures, completely dynamic dispatch and so on. Why is it that dynamic languages all seem to have these features, where many statically-typed languages don’t? I believe a primary reason is that these features are easier to implement in dynamic languages. It’s not that it is impossible to support such features in static languages — in fact many static languages do support them — but rather that creating a flexible enough type system is a challenge.
Probably the most obvious example is duck typing. This is a feature of dynamic languages that removes complexity from the language implementation. With duck-typing, the implementation need not inspect or infer anything, it just tries its best to dispatch at runtime and throws an error if it can’t. Compare this with the complexity of implementing a static type system capable of full inference and/or a reasonable alternative like Scala’s Structural Types.
So where is the problem? Well, having these features in dynamic languages is a wonderful thing, but it comes at a cost:
- No static verification. Without this verification, we need to do more work to test our code. And because testing isn’t perfect, we risk more bugs.
- Less-precisely specified APIs. As APIs contain no type information, they can be harder to read and learn. Documentation helps, but this kind of documentation comes for free (with verification by a compiler) in a statically-typed language.
Essentially, the dynamic languages are giving us more flexibility, but at the same time are shifting other work our way. Shouldn’t we aim for more? From what we know about shifting work, shouldn’t we be demanding a language which tackles the complex issues head-on to deliver us this flexibility without the costs?
Are there languages that achieve this already? Classics like ML and Haskell, along with newcomers like Scala at least take aim at these harder issues. The biggest problem has always been pushing the complexity down into the language implementation without having it leak too much into the language itself. This is one of the greater challenges in software, but the closer we get to nailing it the more productive we’ll all become.
Continuous Integration Myth: CI vs Nightly Builds
This particular myth was one I hadn’t anticipated, but I’ve seen variations repeated often enough to convince me that there is some confusion about the relationship between continuous integration and nightly (or indeed daily) builds.
The first point to clarify is that having a build that runs daily is not the same as practicing continuous integration. Daily is just not frequent enough — indeed the goal should be a new build for every change, or continual builds if the former is impossible. Add on top of that the fact that having a build server is not the same as CI, and it’s clear that we are talking about different beasts.
Where things get more interesting is when people start to ask questions like “Is there any value in a nightly build when you are already practicing CI?”. It may seem, if you’re building twenty times a day, that there’s little point building a twenty-first time overnight. But far from making a nightly build redundant, a CI setup can include nightly builds as a complement to the normal continuous builds. Let’s look at some common examples:
- Fast Build/Slow Build: larger projects can often develop a test suite that takes hours to run. Although the goal should be to cut this time down mercilessly, the reality is some forms of testing are slow. A common workaround is to split the slower tests out of the continuous build (to keep it fast), and run a nightly build with the full test suite.
- Nightly Releases: a build can be used to release a full package nightly based on the last known good revision. This is a good example of how the CI build complements the nightly — by identifying the most recent revision that passed all tests, making the nightly releases more reliable.
- Resource Intensive Builds: the idle hours in the night are a great time to run tests that require a lot of resources, as the build can make use of hardware that would normally be tied up during the day.
So, nightly builds are not CI, but at the same time a CI setup should not neglect nightlies altogether.
Devoxx: Future of the JVM
Today’s theme at Devoxx, at least from the talks I chose, was very much the future of the JVM, including the future of Java. Two big things were highlighted: modularity and dynamism.
Modularity
The focus of JDK 7 will be a new module system for Java which will in turn be used to modularise the JDK itself. The plan is to develop the system in the open (no more JSR-277-style project management) as part of the recently-announced Project Jigsaw. I encourage you to read Mark Reinhold’s blog entry for details.
One neat point that stood out for me was the desire to make this fit well with OS packaging systems (think RPMs, .debs, etc) — so it will be trivial to create an OS package for a Java module. This should couple nicely with the easy availability of the Sun JDK on Linux these days (now it is open source), making Java software more integrated with the native platform.
A much more critical point, however, is the idea of versioning as an enabler to make incompatible changes. Even as the news of Java’s death continues to roll in, it appears Sun is looking to put a mechanism in place that will allow them to finally make incompatible changes. Once you have a modular JDK and the ability to express dependencies on particular versions of modules, it follows that it should be possible to make incompatible changes to those modules in new versions. Perhaps in time this will allow a much-needed cleanup of the dark corners of the platform.
This also raises big questions for both OSGi and Maven. I don’t expect either of these entrenched projects to disappear, but there is certainly overlap and a need to adapt. On the OSGi front Sun is aiming for interoperability, but they claim that the Jigsaw module system will go down to a lower level than OSGi is capable (Update: it appears that this claim is controversial, see the comments below.).
Dynamism
Stepping away from Java the language and looking at the JVM platform, Brian Goetz and Alex Buckley spoke about the move “Towards a dynamic VM”. The talk focused on the efforts in JSR-292 (aka the invokedynamic JSR) to make hosting dynamic languages on the JVM easier and more efficient. The key component of this JSR is a new invokedynamic bytecode which can be used for dynamic method dispatch (when the actual method to call depends on more than just the type of the instance it is being invoked on).
The cool thing about invokedynamic is it will allow the various dynamic language runtimes to effectively plug method lookup functionality into the JVM. This will allow each dynamic language implementation, many of which have very flexible method binding, to take full control of method selection. This is key to efficient implementation of these languages on the JVM.
So hey, even if Java has lost its mojo, that isn’t the point anymore. It’s the platform, stupid!
Devoxx Conference Day 1
Conference Day 1 (Devoxx Day 3) is done, and on balance it was decent, but hit-and-miss. “Special guest” RoxorLoops — a Belgian Beatboxer — brought some variety to the opening. He is a seriously talented guy and I think most enjoyed it as I did.
Of course the meat of the conference is the talks. Here’s a rundown of those that I attended:
- Keynote: JavaFX: I have not taken much interest in JavaFX so far, so it was interesting to see a bit of it in action. The most interesting part was the demo of dragging a JavaFX application out of a browser and having it run standalone. It’s high on cool factor, and could be quite useful (though I doubt any user will think themselves to try it, so…).
- Keynote: Java and RFID: IBM and partners managed to take an interesting idea, namely running a live project at the conference tracking attendees with RFID, and turn it into a yawn-worthy presentation. I kept wanting to see the actual software details behind it (not which RFID printers I can buy…). When they did get to some software stuff, it felt like seriously over-engineered ADD (Acronym Driven Development).
- From Concurrent to Parallel: Brian Goetz gave a polished overview of the fork-join framework. I’m into java.util.concurrent, so it’s good to get a look at the next logical step.
- Effective Pairing: The Good, the Bad and the Ugly: Dave Nicolette had previously done this talk with rehearsed players for various pairing scenarios. As the players weren’t available, Dave took the ambitious route of getting audience volunteers to ad-lib instead. It didn’t go too badly considering the obstacles (e.g. audio not set up for the job), but on balance it was probably too ambitious. At least the audience did get involved, though.
- The Feel of Scala: this was my favourite of the day. Bill Venners is a very clear speaker, and this talk was polished (perhaps done before). I enjoyed the focus on real code samples, which were presented in an easily-followed fashion. Bill’s own motivations for using Scala reminded me of my own desire to check it out, which I now plan to do more seriously than before.
- Filthy Rich Android Clients: I’m planning to get a G1 so thought I’d check out some eye candy. Sadly, this talk was much too heavy on details and not enough on illustration. Learning how things work is great, but packing slides full of points won’t do it – there needs to be more sample code/hands on work. And this topic was just crying out for some eye-catching demos, of which there were too few in my opinion.
- Jython: Jythonistas Jim Baker and Tobias Ivarsson made a sometimes-awkward pairing for this talk. They focused too much on Python and Django and not enough on Jython itself for my taste. These are fine topics and we even use Django for zutubi.com, but I was expecting more content about Jython and cool ways to leverage Python on the Java platform. They did cover some of this territory, and get full marks for live coding and real demos.
Oh, and free beer and frites is always a good way to end a day…
Don’t Be Attached to Your Code
When I started developing, I used to feel a great sense of achievement in producing large quantities of code. A large line count was a thing to be proud of. Fast forward to today, and I see a large line count a lot differently. Experience has taught me that more code means more to maintain, and more maintenance slows me down. Hence these days I am always looking for ways to get the line count down, rather than being happy to see it climb.
Keeping ‘Em Down
How do you keep the lines down? Well, there are two obvious ways, both of which work well:
- Don’t write the code the first place. The quantity of open source code available these days is simply incredible. A large part of any but the most unusual project can be solved by gluing together available solutions. The best part is that an active open source project will not only be maintained by someone else, but constantly improved!
- Just delete it. Don’t be attached to code you have written: always be on the lookout for code that has passed its useful lifetime. I’ve touched on this topic before, in my earlier post on why you should delete your code.
Both solutions have their enemies: Not Invented Here for 1 (a post all of its own) and code attachment for 2.
Blood, Sweat and Tears
But what about all that effort that went into the code in the first place? It is natural to feel a sense of waste when you delete your own code. This is the kind of attachment that you need to fight. The thing is: the effort was not wasted. The code has served a purpose, not least as a stepping stone to the next revision. The real waste occurs when the cost of maintenance outweighs the value of the code that you are reluctant to delete.
What Happened To Pride?
I am not saying you should not take pride in what you create. But what you create is not the code: it is the product. When deleting code, you do it to improve the product. Not just for now, but for the future with the time you will save not maintaining the dead weight. Deleting is a necessary step in the continual improvement of your codebase.
A great recent illustration of this appeared in Jeff Atwood’s post Quantity Always Trumps Quality. The best results are rarely produced on the first attempt!
Making It Habit
Once I cast off my attachment, I found deleting code to be enjoyable. Nothing is better than watching your product grow and expand while the line count stays flat or even drops. In Pulse 2 we took the opportunity to refactor the code that powers the configuration UI. The amount of dead weight we could remove as part of this refactoring was quite incredible. Best of all it was also the most tedious part of the codebase to maintain!
I have also found that without attachment, deleting code becomes habit. It’s not just about major refactoring: it changes how I write code day-to-day. I was reminded of this by James Golick’s recent post Wearing Out My Delete Key, which discusses just how deleting code should be a normal part of your day.
Cut Away the Ball and Chain
If you haven’t discovered the joy of deleting, give it a try. Always question attachment to your code: is it based on what the code is doing for you now or how much effort you put into it in the past?
Tag Clouds: Why?
Maybe my brain just doesn’t work in a way that appreciates them, but I really don’t see the point of tag clouds. Sure, adding a cloud makes your site feel oh-so 2.0, but does it really accomplish anything? Is there some advantage over a sorted list? Do people actually use tag clouds?
I find them annoying because they:
- Take up excess space (especially for the larger font sizes).
- Are hard to decipher, as the text is in a variety of sizes and is thus difficult to scan.
- Feel like a trend, followed mindlessly.
When the information is useful I would prefer it to be presented as sorted and/or coloured list of a uniform font size. I for one would be quite happy to see these useless jumbles of letters disappear!
Ext Discovers Step 2 of the Slashdot Business Model?
For many years, step 2 has eluded the slashdot community:
1: Start your project.
2: …
3. Profit!
Now, however, Ext, the company behind the popular ExtJS Javascript library, seem to believe they have pinned down this step. In the latest 2.1 release, Ext has switched from a dual LGPL/commercial license model to a dual GPL/commercial license model. Despite claims from the company that this was done due to community concerns about ExtJS not being fully open-source, the majority have seen what this really is:
1: Start your project under a LGPL/commercial license model.
2: Switch to a GPL/commercial license model.
3: Profit!
The model works because step 1 allows you to build a community around the more liberal LGPL license. In particular, as the LGPL is commercial-friendly, the community will include many people building commercial applications. Once the community is suckered in and committed, the license is changed, leaving them high and dry. Well, not quite: they can continue to use new versions of the library by buying a commercial license. Hence the profit!
Not surprisingly, this sudden license switch has caused a large community backlash. People don’t like to feel that they have been baited in this way. The defense from Ext runs along a couple of lines:
- They are just applying the “Quid-Pro-Quo” principle: i.e. if you get something out of Ext, you should give back. This is fine: Ext have created a great library and have every right to charge for it if they wish. But it isn’t the use of a commercial model that is wrong here: it is the sudden switching of models. Ext have massively benefitted themselves from liberal licenses, both in terms of the libraries Ext was originally built around (e.g. YUI which is BSD licensed) and the community that appeared around Ext itself, submitting bug reports, patches and extensions. What are they now giving back to these communities they have used?
- The previous licensing was confusing and criticised for not being “open” enough. Simplifying the licensing scheme is fine, but there was no need to change to the GPL to do this. In fact, switching to the GPL has caused more problems for open source projects built around Ext than it has solved. Because of the viral nature of the GPL, those projects must now reconsider their own licenses to be able to upgrade to the latest version of ExtJS. The Ext team surely realise this, so trying to give this reason for the license switch is misleading on their part.
The backlash has been all the greater because of how the switch has been handled:
- The community was given no warning or consultation, despite this change being ostensibly for their benefit.
- Ext were not forthright with the real motive for the change.
- Ext are claiming that a fork of the existing 2.0 version is not legal, due to the way they applied the LGPL. This is likely to be incorrect, and if correct then their use of the name LGPL was grossly misleading.
- There is still confusion around the licensing. For example, the commercial license does not clearly spell out what happens when upgrading. Debates continue around the applicability of the GPL to hosted applications and those that generate code. Ext have been far from responsive on these matters.
- This is not the first major license change for ExtJS, leaving many anticipating similar upheaval in the future.
The saddest part about this is that the Ext team really have built a fantastic library, and a vibrant community around it. The library had all the hallmarks of an open source success story. Now, however, Ext have committed the cardinal sin of an open source project: they have undermined the trust of their own community. I can see the strategy making a short term profit, and perhaps even a long term business. I cannot, however, see the community returning to full strength. In the long run, although Ext may have a successful commercial offering, they will lose a large part of their current and potential community to competing and still-open projects. The power of the community will see those competitors flourish.
You are currently browsing the archives for the Opinion category.
Where Am I?


A little madness is the blog of Daniel Ostermeier and Jason Sankey. We are the founders of zutubi, a company based in Sydney, Australia that makes software for software developers.
Our flagship product is Pulse, an easy to use yet powerful and adaptable continuous integration server. We’d love you to try it free today!